Method
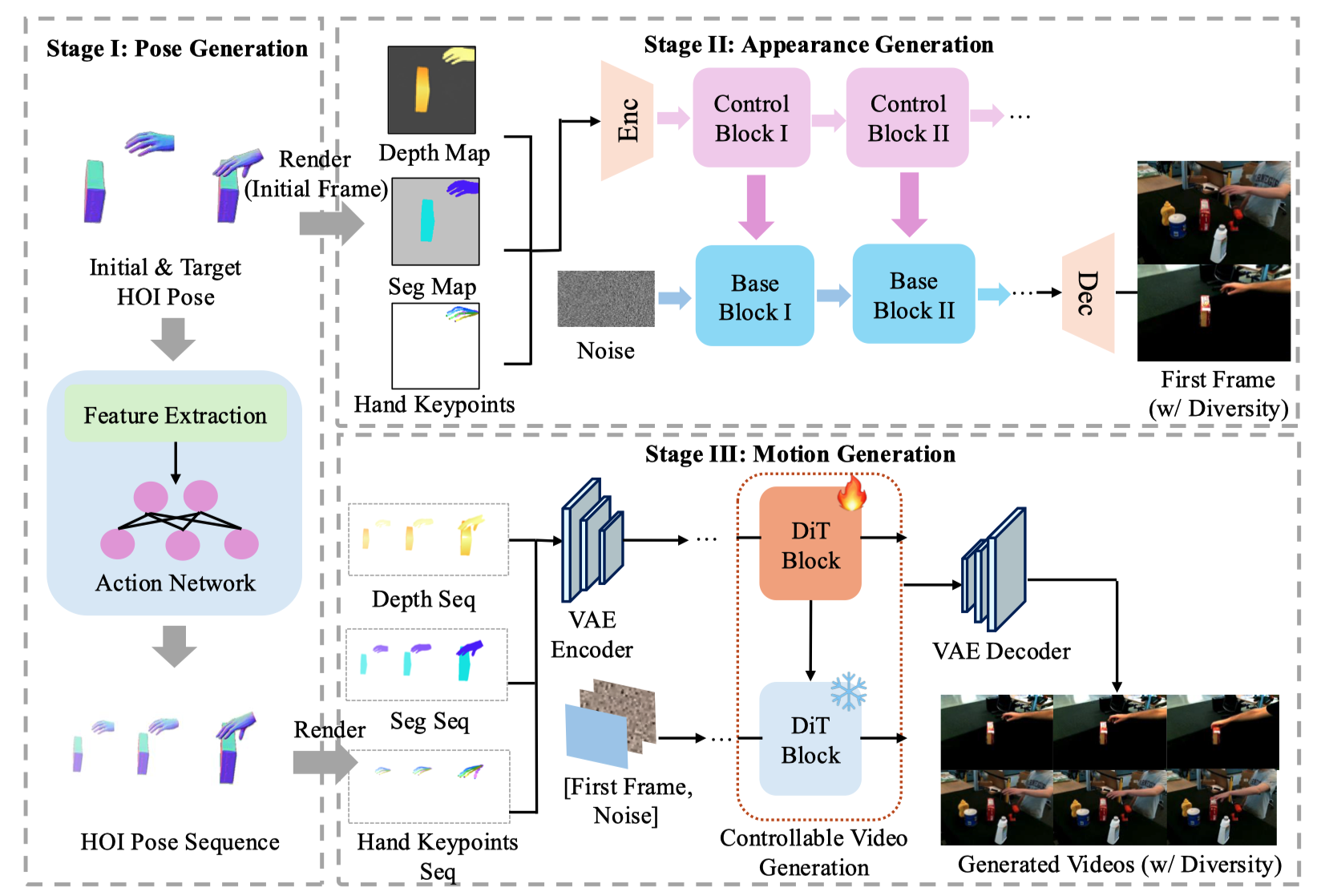
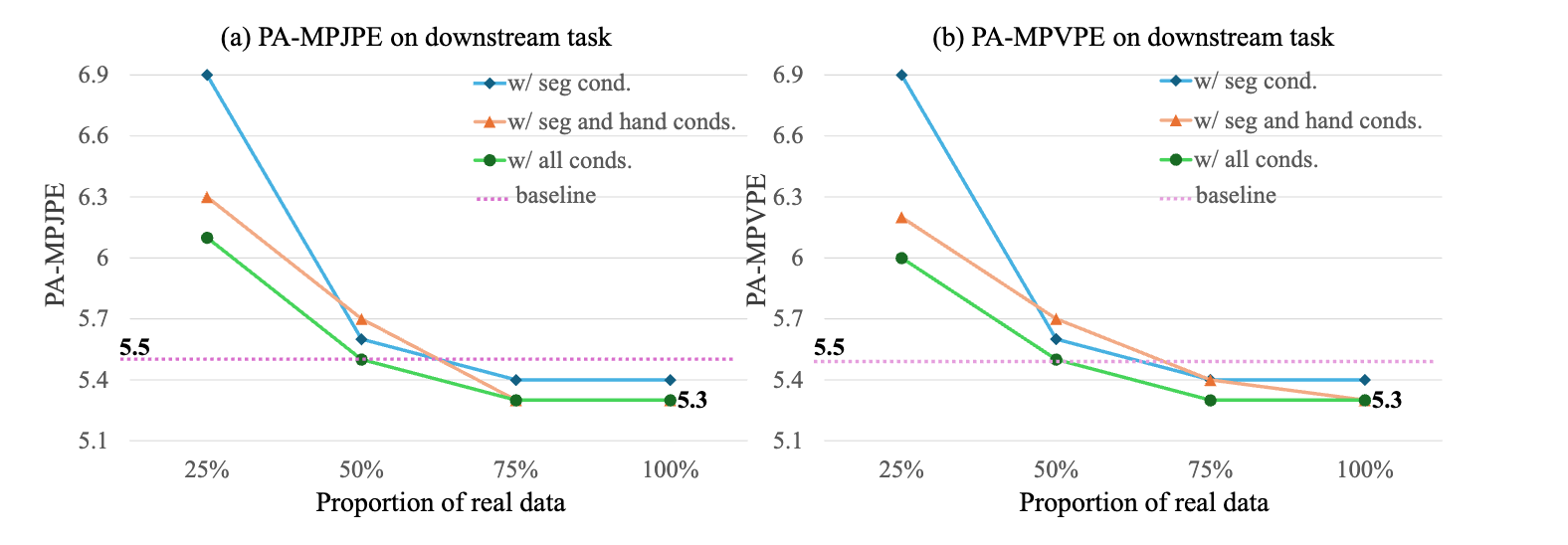
Overview of our three-stage generation pipeline. (1) Pose Generation: A pretrained pose generation model generates the intermediate hand-object interaction (HOI) poses based on the initial and target poses, along with the object mesh. (2) Appearance Generation: A controllable image diffusion model synthesizes the first frame of the video, conditioned on multi-modal inputs (depth maps, semantic masks, and keypoint annotations). (3) Motion Generation: The generated HOI sequence and the first frame are rendered into a full video sequence by a video diffusion model, conditioned on the same multi-modal inputs used in the appearance generation stage.